Right now I’m setting up a project aimed at crop evaluation over ortophotos, HR and VHR imagery. All the steps of evaluation will be done in QGIS with PostGIS used for data storage and post-processing.
In the initial phase, fifteen GIS operators will be using QGIS to reshape geometries and fill attribute data accordingly. Fifteen are not so many, but it is enough to be a possible source of errors. Luckily, there are many things you can do with QGIS to prevent people from making mistakes.
QGIS project file
QGIS project, the .qgs file, is a pure XML and, unlike ESRI’s .mxd, can be edited with any text editor. That’s great advantage when you need to prepare one project for many different operators. My project has to load some database layers that should be different for different operators that have different database accounts.
How do you do that? It’s enough to create a project using your own credentials and then replace them with USERNAME and PASSWORD strings as seen below. What happens when the user loads the project?
A popup window will be shown asking him/her to handle bad layers, as QGIS will not be able to connect to the layer. When he/she fills in right credentials (just once), the layer will be loaded. Don’t forget to use a table name that doesn’t exist, QGIS will use the credentials stored with PostGIS connection otherwise and won’t ask for them. I don’t like this behaviour.
Using this multiple times for each user-specific layer is a great time saver.
Adjust attribute table to fit your needs
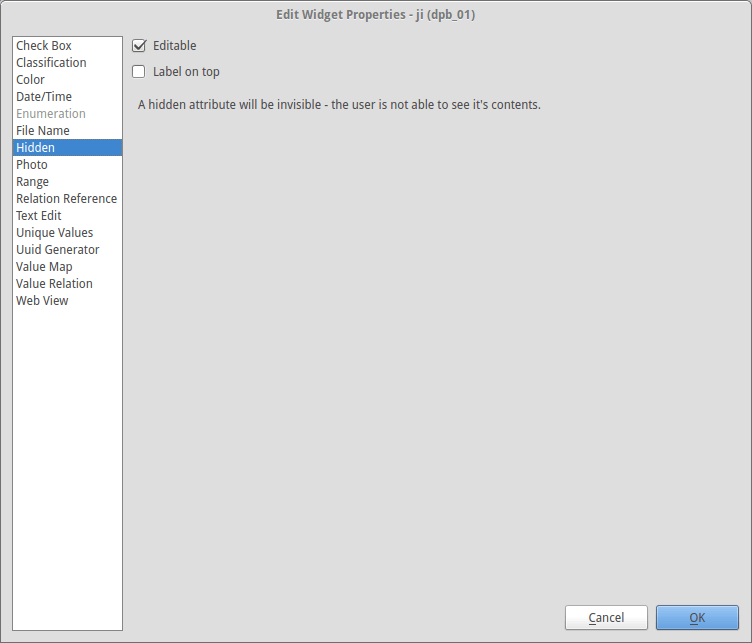
QGIS attribute table has so many settings you probably don’t use on daily basis and yet they might be invaluable in such project. All of them are available from layer properties under the Fields tab.
Sadly, our PostGIS layers are very wide in terms of column count. Not all of the columns are to be edited or even seen by operators, so it might be a good idea to hide them by setting their Edit Widget to Hidden. Those that should be seen, but not edited, might be set as not editable by unchecking that option.
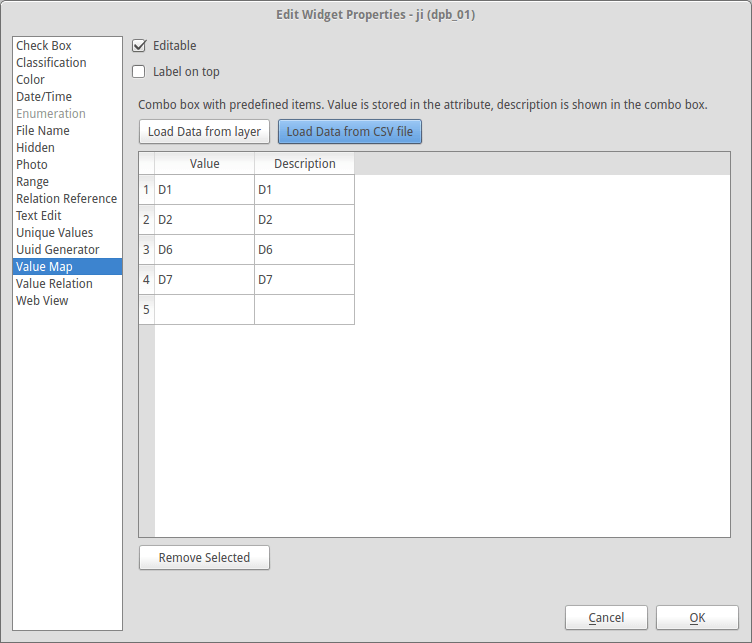
Lots of our attributes use enumerations provided by our project partner as CSV files. We use them in QGIS as value maps, so operators don’t have to type them manually - we both make their work easier and eliminate mistakes they made.
Note QGIS swallows the first row of the given CSV file as if it was a header. Don’t forget about this when creating your own enumerations. Once set, operators will see a friendly combo box instead of a hostile blank input in the attribute table.
These are just small adjustments that can make a big difference in your QGIS workflow.
I’ve been running some GRASS/PostGIS computations on a remote server that were taking hours to finish. Once in a while I checked for their state by issuing tail log_XX.log from my laptop to see if they were ready yet. It suddenly became pretty annoying to check five different logs every ten minutes.
Instead of waiting and checking the logs, I thought it would be great to automate this. And it would be awesome if checking was fun. So I wrote a simple routine that takes log number as an argument (every process logs to a separate logfile) and checks it every minute until it says done. Right after that notify-send gives me a neat popup and Queen starts playing their We are the champions thanks to mpg123.
Using SVG to build web maps have both pros and cons and to be honest I don’t know any serious map/GIS project built on top of SVG. However, as a part of my job at university, I was forced to use both SVG and SMIL to produce animated web map (see the small version below or the big one at GitHub) and I’d like to share my findings.
Animate destinations one by one. They are revealed in order of their distance from PRG.
Animate airways.
Once airways are animated, animate airplanes along their path from PRG to their destination in order of their time of departure.
Profit.
My goal was to create an animation of all departures from Vaclav Havel airport during one day. These data can be obtained at FlightStats, I didn’t find a way make this process automatic though. OpenFlights might be better source then.
SVG creation
Kartograph is a great tool both for SVG generation and scripting. What a pity it’s probably a dead project according to the last commit date. After installing Python part of library used to create SVG files out of vector geometries, it can be run with something like this:
It is possible to adjust map settings in many different ways. The most important/interesting:
Choose what attributes you want to have exported from source file with attributes key for every layer. They’ll be available as data- attribute of SVG elements.
It comes with Grid generation packed in! Really great. Sea generation works for some projections only.
Set the projections you want to use with additional settings.
bounds settings should - according to the docs - use layer extent as well, I couldn’t make it work though. Use [-180, -90, 180, 90] as a workaround to get the whole world. Don’t forget to set padding, so your map doesn’t get clipped on edges.
exporting coordinates rounded to one decimal place makes your SVG a lot smaller.
You can change SVG look with simple CSS, just be sure to use layer names as CSS ids:
SMIL is a XML based language for multimedia representation. It comes ready for timing, animation, visual transitions etc. I guess it might be considered easier to read for a web development beginner. Once you start using it, you immediately realize it suffers from the same disease like XML does: it is so wordy!
Let’s get back to my example. To animate airports one by one, let’s give them unique ids, so they look something like:
That’s something you do by hand as kartograph doesn’t give ids to SVG elements. Once you’re done with that, you can run SMIL animation. If you look closer at the final map, you’ll notice there are three properties animated for each airport: fill opacity, stroke opacity and radius. Each property needs to use separate SMIL<animate />, which might look like the one below:
I guess you get the idea how long this would take for more airports. Make sure to notice that SMIL can start animation based on another animation’s end (osr_ani.end) - that’s pretty neat.
Airways animation works almost the same. First, add unique id to each airway:
Once airways animation has finished, let airplanes fly around the globe with a simple JavaScript function:
/** * @param number coef scale radius by number of flights to the given destination * @param string flight_id */varcircle=function(coef,flight_id,timeshift){varsvgns="http://www.w3.org/2000/svg"; var svgDocument =document; var motion = svgDocument.createElementNS(svgns,"animateMotion"); var animation = svgDocument.createElementNS(svgns,"animate"); var shape = svgDocument.createElementNS(svgns, "circle"); var time = 15 + timeshift; var dur = document.getElementById(flight_id).getAttributeNS(null, "data-dist")/100; motion.setAttribute("begin", time + "s"); motion.setAttribute("dur", dur + "s"); motion.setAttribute("path", document.getElementById(flight_id).getAttributeNS(null, "d")); motion.setAttribute("xlink:href", "#" + flight_id); motion.setAttribute("id", flight_id + "_motion"); animation.setAttribute("attributeName", "opacity"); animation.setAttribute("from", "1"); animation.setAttribute("to", "0"); animation.setAttribute("begin", time + dur + "s"); animation.setAttribute("dur", "0.1s"); animation.setAttribute("fill", "freeze"); shape.setAttributeNS(null, "r", 1*coef); shape.setAttributeNS(null, "fill", "1f78b4"); shape.setAttributeNS(null, "stroke", "1f78b4"); shape.setAttribute("id", "airplane-" + flight_id); shape.appendChild(motion); shape.appendChild(animation); document.getElementById("airplanes").appendChild(shape);}
SMIL with SVG seems to be interesting option for web map animation, a bit lengthy though. Syncing animations can easily become pain in the ass (see StackOverflow thread). Never call your function animate - there is namesake function defined in Web Animations API that makes animation crash in Chrome. <animateMotion /> is a great tool to animate elements along path.
A supervisor of a project I’ve been working on came up with a task that totally buried the previous process in a blink of an eye: Give me the buffer (diffed with original geometries) that is smoothed on the outer bounds so there are no edges shorter than 10 cm. I sighed. Then, I cursed. Then, I gave it a try with PostGIS. Achieving this goal involves these steps:
Dissolve intersecting buffers
Run some kind of generalization algorithm that is not defined in PostGIS
Diff original geometries
Cut buffer with grid so it is faster not so slow for the next steps
Two of those four are rather problematic with PostGIS: line smoothing and diffing the original geometries (I didn’t get to the last one, so it might be 3 of 4 as well).
Hello, I’m GRASS
I haven’t used GRASS for ages and even back then I didn’t get to know it much, but it saved the day for me this time.
grass -text path/to/mapset -c
v.in.ogr input="PG:host=localhost dbname=db user=postgres password=postgres"output=ilot_050 layer=ilot_2015_050 snap=-1 --overwrite
# turn the snapping off, I don't want the input changed in any way, even though it is not topologically valid
v.in.ogr input="PG:host=localhost dbname=db user=postgres password=postgres"output=lollipops_050 layer=lollipops.lollipops_2015_050_tmp snap=-1 --overwrite
v.in.ogr input="PG:host=localhost dbname=db user=postgres password=postgres"output=holes_050 layer=phase_3.holes_050 snap=-1 --overwrite
v.db.addcolumn map=ilot_050 columns="id_0 int"
v.db.update map=ilot_050 column=id_0 value=1# dissolve didn't work without a column specified, dunno why
v.dissolve input=ilot_050 column=id_0 output=ilot_050_dissolve --overwrite
v.buffer input=ilot_050_dissolve output=ilot_050_buffer distance=20 --overwrite
# v.out and v.in routine used just because I didn't get the way attributes work in GRASS, would do it differently next time
v.out.ogr input=ilot_050_buffer output=ilot_050_buffer format=ESRI_Shapefile --overwrite
v.in.ogr input=ilot_050_buffer output=ilot_050_buffer snap=-1 --overwrite
v.overlay ainput=ilot_050_buffer binput=holes_050 operator=or output=combined_050_01 snap=-1 --overwrite
# tried v.patch to combine the three layers, it gave some strange results in the final overlay
v.overlay ainput=combined_050_01 binput=lollipops_050 operator=or output=combined_050_02 snap=-1 --overwrite
v.out.ogr input=combined_050_02 output=combined_050 format=ESRI_Shapefile --overwrite
v.in.ogr input=combined_050 output=combined_050_in snap=-1 --overwrite
v.db.addcolumn map=combined_050_in columns="id_1 int"
v.db.update map=combined_050_in column=id_1 value=1
v.dissolve input=combined_050_in column=id_1 output=combined_050_dissolve --overwrite
# get rid of < 10cm edges
v.generalize input=combined_050_dissolve output=combined_050_gen method=reduction threshold=0.1 --overwrite
v.out.ogr input=combined_050_gen output=combined_050_gen format=ESRI_Shapefile --overwrite
v.in.ogr input=combined_050_gen output=combined_050_gen snap=-1 --overwrite
v.overlay ainput=combined_050_gen binput=ilot_050 operator=not snap=1e-05 --overwrite output=ilot_050_diff
v.out.postgis input=ilot_050_diff output="PG:dbname=db user=postgres password=postgres"output_layer=onf3.buffer_050_diff options="GEOMETRY_NAME=wkb_geometry,SRID=2154" --overwrite
v.in.ogr input="PG:host=localhost dbname=ign user=postgres password=postgres"output=buffer_050 layer=onf3.buffer_050_diff snap=-1 --overwrite
v.in.ogr input="PG:host=localhost dbname=ign user=postgres password=postgres"output=grid layer=grid snap=-1 --overwrite
v.db.connect -d map=buffer_050
# instead of v.out and v.in routine
db.connect driver=sqlite database='$GISDBASE/$LOCATION_NAME/$MAPSET/sqlite.db'
v.db.addtable map=buffer_050
v.overlay ainput=buffer_050 binput=grid operator=and output=buffer_050_grid snap=-1 --overwrite
v.out.postgis input=buffer_050_grid output="PG:dbname=ign user=postgres password=postgres"output_layer=onf3.buffer_050_diff_grid options="GEOMETRY_NAME=wkb_geometry,SRID=2154" --overwrite
It is damn fast compared to PostGIS. It can be automated. It can be parametrized. It is robust. It is great!
Lesson learned
You cannot smooth lines by deleting edges shorter than n in PostGIS. At least I haven’t found the way to do so without defining your own procedure. You can with GRASS.
GRASS reduction algorithm always keep first and last node untouched. Thus, if they’re closer than n, they’ll stay even if you’d like to have them deleted.
Getting to grips with GRASS attribute data is rather hard after using shapefiles all your GIS life.
It is great to exploit synergy of different GIS tools used for what they’re best at.
The more I work with big data, the more I get used to not seeing them. That’s kind of a twist after crafting maps at university.
At CleverMaps we heavily rely on the cadastre of real estate, which is probably the biggest data source in my country. Using their excellent knowledge of this data set, my teammates often supply me with all kinds of weird challenges.
Give me the biggest land users nearby
Find the biggest land users in surrounding cadastral communities for each cadastral community (~ 13K) being the latest task, here’s the query I tackled it with:
WITH users_ AS (
SELECT
cad_code,
id,
zipcode,
city,
concat_ws(' ',street, concat_ws('/', house_number, street_number)) as street,
name,
'Users with more than 10 ha'::text note,
SUM(acreage) area
FROM land_blocks -- being a table with info about all the agricultural land blocks
JOIN users u ON id_uz = id
GROUP BY cad_code, u.id
HAVING SUM(acreage) > 10
),
ints AS (
SELECT
ku.cad_code as community,
ku2.cad_code as surrounding,
ku2.cad_name
FROM cadastral_community ku
JOIN cadastral_community ku2
ON ST_Intersects(ku.geom, ku2.geom)
WHERE ku.cad_code <> ku2.cad_code
)
SELECT
DISTINCT ON (surrounding, cad_name, u.zipcode, u.city, u.street, u.name)
surrounding,
cad_name,
u.zipcode,
u.city,
u.street,
u.name,
u.note,
u.area
FROM
users_ u
JOIN ints
ON cad_code = community;
Few things to note:
concat_ws() is a great function for joining values that might be NULL. If such a value is found, it is skipped and the function continues with the next one (if any). Thus, you’ll never get a string ending with a trailing slash (Street name 55/).
With users_CTE I get a list of owners having more than 10 hectares of land for each cadastral community. This gives me the inverse result of what I want (if I know the biggest owners in the cadastral community, I know these are the ones that should be listed for surrounding c. communities).
This putting-it-all-together step is done with intsCTE that outputs the list of surrounding c. communities for each of them.
DISTINCT ON cleans up the list so the same owners don’t appear more than once for any given c. community.
Writing this makes me realize the list should be probably sorted by area so only the occurence with the biggest value is kept for each c. community. Simple ORDER BY should deal with this just fine. Or even more sophisticated, using GROUP BY to output the total acreage in all surrounding c. communities.
{kind=link}